
Data set and data elements
Quality over quantity
The elements of data you include in your registry must relate to its specific objectives. Each must have potential value in the context of the current clinical and scientific climate and be chosen by a team of experts, including biostatisticians, epidemiologists, and data scientists. Selecting data elements for a registry is best done in a stepwise manner.

Choosing the data elements for a registry starts with the identification of the data domains:
You should choose data elements that best define the domain from which the data elements will be collected. Each data element should also be congruent with the purpose of the registry and be an answer to the questions that the registry is trying to address. The most effective way to select data elements is to start with the registry purpose and objectives and then decide what types of groupings, measurements, or calculations will be needed to analyze them. There are a few general principles that might help you with this.
There are two ways you can minimise the burden of data collection:
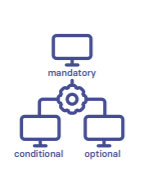 |
Agree on a minimum (or core) dataset – the data elements you feel are essential for every case/patient/subject. When deciding on your dataset, you should carefully consider and specify if a data element is (a) mandatory, i.e., must always be collected, (b) conditional, i.e., should be collected if a certain condition is met, or (c) optional. These latter optional variables will be more descriptive or exploratory and are helpful, but not essential, to know. Deciding to include these must take into account the burden of data collection and entry. For example, while it may be desirable to adjust for confounding variables in registry analyses, including a broad range of potential confounders in a dataset has to be weighed against the additional burden and costs this brings, as well as the possible impact it will have on data completeness of other non-optional items. |
 |
Identifying alternative, existing sources for your data items – if some data items are already being collected by another organization, serious consideration should be given to whether these also need to be collected as primary data by you or whether they can be obtained through linkage. This will include assessing the burden of repeated data collection, the quality of the other source, and the accessibility of the data in the other source (see section “Data sources.”) |
You should only include reliable information in your dataset.
 |
Use standard data terminologies and code lists, such as the International Classification of Diseases (ICD), Systematized Nomenclature of Medicine (SNOMED CT), the Classification of Interventions and Procedures (OPCS), the Logical Observation Identifiers Names and Codes (LOINC), and the European Renal Association primary renal disease codes. This will simplify the element selection process and promote consistency, comparability, and a shared understanding of the data elements within and between other registries. It can also decrease the training needs and the data abstraction burden on sites. For some data elements, you may need to create your own definition; when doing so, seek advice and examples from existing registries and pilot your definitions to make sure they are unambiguous. A data dictionary that records these decisions about names, purpose, and value domains (see below) will ensure that staff in sites collect the information in the same way, increasing internal validity and making it easier for others to interpret and use the data. This data dictionary should be easily accessible and usable by others (e.g., published on the registry website). |
 |
Set value domains for each data element. These value domains can be numbered (enumerated), e.g., 1=male, 2=female, or categorized (non-enumerated). For categorised data, the value domain is a description, e.g., a value domain for a person’s age might be “18 years and older”. You should include value domains for missing or unknown data, e.g., missing=999, unknown=0. |
 |
Set validation rules to improve the quality of the data and reduce errors. These can function at the data collection interface or database level, depending on how data entry occurs. Validation rules include setting the format of data entered and possible ranges of values, e.g., a person’s age cannot be above 120 years, and the date of a kidney transplant cannot be a future date. Remember to take into account internal consistency, e.g., if a person’s age is above 55, it is unlikely they will be pregnant. |
When selecting and developing data elements, you should take into account security policies and privacy issues (see section “Legal ethical and privacy issues”).
It is good practice to create a methodological guide with detailed information on what and how data should be collected. This will help guide others when collecting the data for your registry. In addition to the data dictionary mentioned above, which is usually in tabular form, you might consider creating a visual representation. The latter is particularly useful when data is flowing from a range of sources with different permissions.
When the first version of the registry dataset is developed, you should test it. Testing not only determines its validity but also evaluates the burden of collecting information – the time, cost and resources that will be needed. Each data item should be considered individually:
- Are the definitions, rules, and descriptors complete, correct, and clear?
- Are there likely to be logistical problems collecting the item?
- Is the clinician or patient burden of collecting the item likely to impact returns?
- Do the data collection system and materials make sense to users – does they have face validity?
Then, in practice:
- Do data get returned for most patients, i.e., is the missing rate low?
- Are the data returns accurate against a gold standard, i.e., is the content validity high? For this purpose, the gold standard is often considered to be data collected directly from its source, e.g., the clinical care record, by trained abstractors following strict operational criteria.
If your registry runs over a long period, you may find that the data elements or the indicators for policymaking change. When changing the data elements, you should do everything possible to allow longitudinal comparability.