
Detail
Define the scope and rigor needed
The scope should be based on the objectives of the registry, but other factors, including but not limited to feasibility, are likely to ultimately shape it.
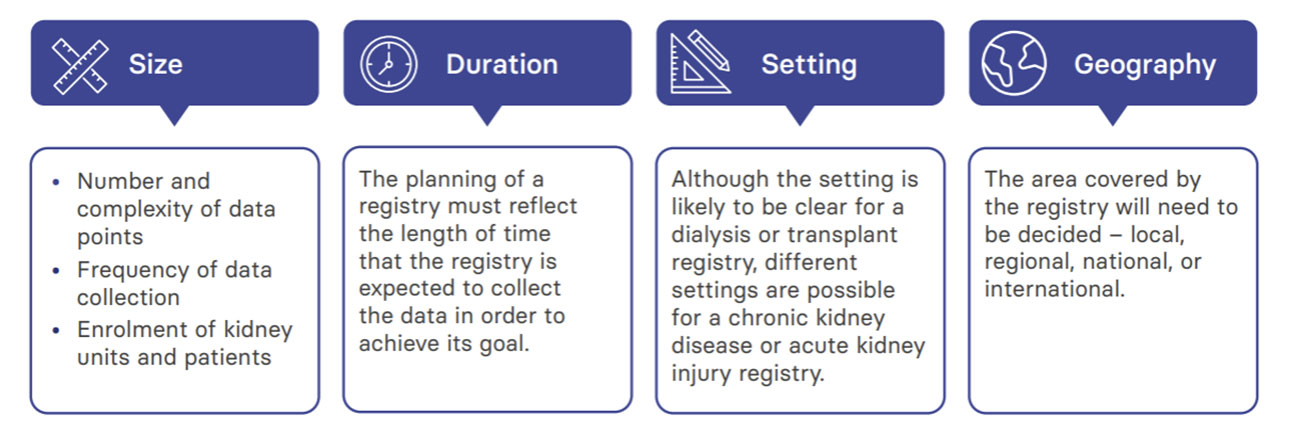
First, agree on the objectives
Before your advisory committee can consider the scope of your registry, it must agree to its objectives. These are likely to fall under the following broad themes:
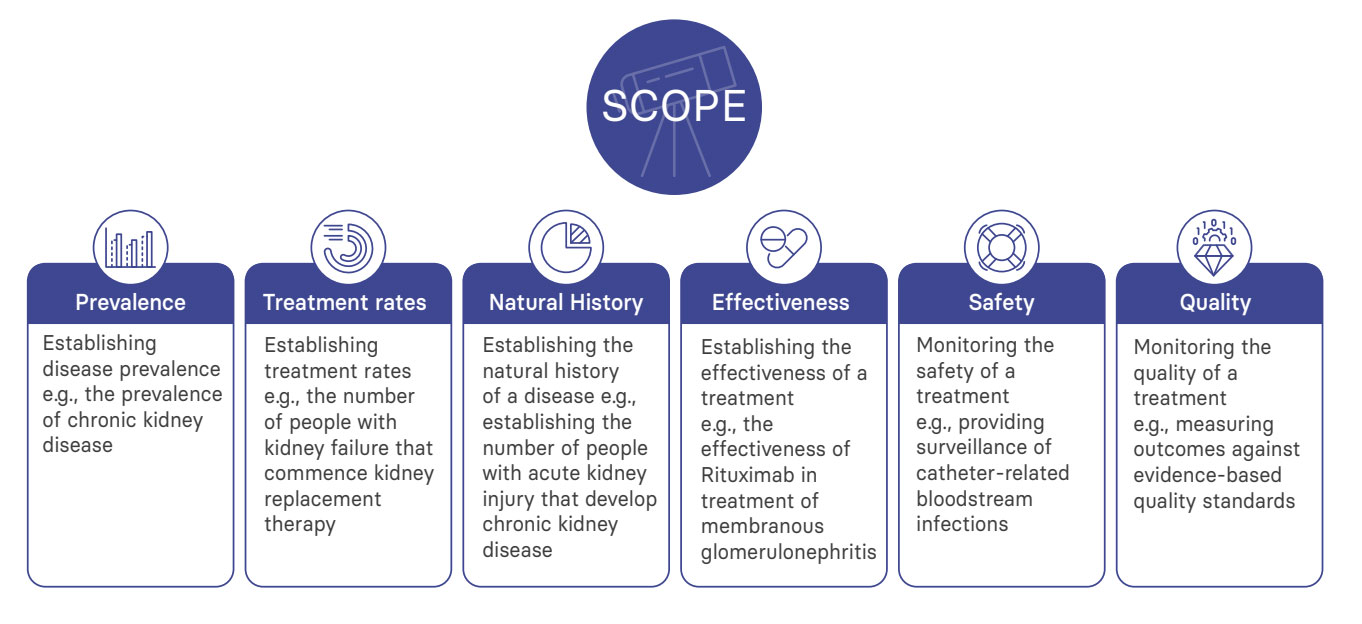
Registries are particularly suitable for the following situations:
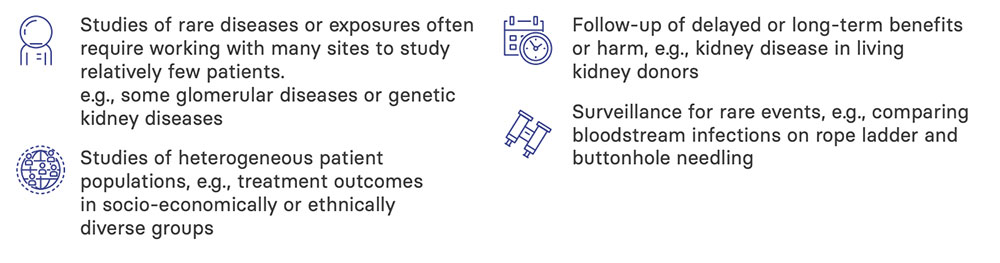
With the goal(s) of your registry agreed upon, you can move on to make decisions on your target population (sites and participants), the variables you need to collect (exposures, outcomes and confounders), and where your data will come from.
The purpose of your registry will be to provide information about a specific patient population for whom the results will be applicable.
You will need to carefully select the population of patients you are going to include in your registry, usually by defining an exposure, e.g.:
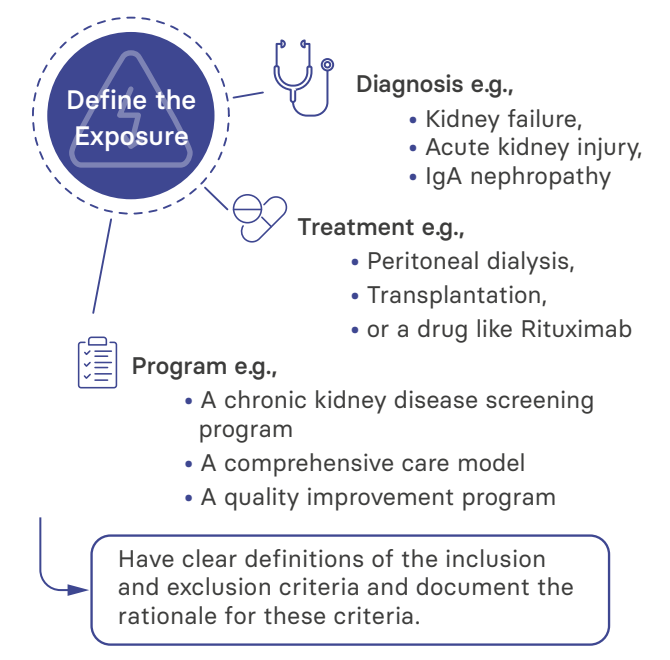 Selecting patients for a registry is a multistage process. It should begin with an understanding of the target population. This is particularly important if you will not include the whole population in your registry (e.g., if participation will not be mandatory as a condition of service provision or access to a drug). To do this, you will need to have clear definitions of the inclusion and exclusion criteria and document the rationale for these criteria. A common feature of registries is that they have less inclusion and exclusion criteria, enhancing their applicability to a broader population.
Selecting patients for a registry is a multistage process. It should begin with an understanding of the target population. This is particularly important if you will not include the whole population in your registry (e.g., if participation will not be mandatory as a condition of service provision or access to a drug). To do this, you will need to have clear definitions of the inclusion and exclusion criteria and document the rationale for these criteria. A common feature of registries is that they have less inclusion and exclusion criteria, enhancing their applicability to a broader population.
After you identify your patient population, you should next select the institutions and providers from which patients will be included in your registry.
The risk of bias in registries
Bias is the result of systematic errors in study design. It can affect:
- Internal validity – the likelihood that the associations you report are true and not due to the effects of variables you have been unable to measure
- External validity – the likelihood that the associations you report would apply in another setting, also known as applicability or generalizability
By their observational nature, registries have the potential to introduce biases that can impact internal and external validity, for example:
- Information bias: if data validity or accuracy are impaired
- Confounding by indication bias: if patient factors determine allocation to a treatment
- Selection bias: if some sub-groups of patients or sites are systematically excluded
- Attrition bias: if loss to follow-up is different between sub-groups of patients
Therefore, it is important to assess the magnitude and impact of any potential bias in your planned registry and evaluate all approaches to minimize this.
If you are not including all patients in all sites in your registry, it will be important to report characteristics of included patients and sites so that others reading your reports can better understand if the results apply to them. If your data source is a healthcare organization, summary data for included patients can be compared with all the other patients. Another summary tool you can use is sequential screening logs, in which all subjects fitting the inclusion criteria are recorded along with a few key data. These approaches will allow you to undertake a quantitative assessment of the likely impact of bias and the sensitivity of your findings to varying assumptions.
When deciding on the data to include in your registry, using a scientific approach to consider how each will be used to address your agreed objectives is helpful. Exposures are the treatments, procedures, health care services, and diseases that you will want to study to better understand their effect on the status of a patient, i.e., the outcome. When considering these, you must also consider potential confounding variables, which can complicate relationships between exposures and outcomes.
| Objective | Exposure | Confounders | Outcome |
|---|---|---|---|
| To determine whether patients using a particular kidney replacement therapy are better able to perform activities of daily living than others | Modalities of kidney replacement therapy | Demographics, primary kidney disease, co-morbidities | Ability to independently perform key activities related to daily living (patient-reported) |
| To determine whether kidney transplant rejection rates vary according to immunosuppression regimen | Immunosuppression therapy | Demographics, prior sensitisation, HLA match, ischaemia times | Kidney transplant rejection |
| Exposures, confounders, and outcomes relevant to two possible registry objectives. | |||
You may need to include additional information about your exposure variables, such as dosage, duration, route of exposure, or adherence. At every stage, however, you must strive to address your registry objectives as efficiently as possible.
Registry data can be obtained from patients, clinicians, medical records, and linkage with other sources. Most renal registries are longitudinal in design, registering patients over time and following them up to evaluate outcomes. Patient registration is best done as they become eligible throughout the year, as this minimizes the risk of eligible patients dying before they are registered (and not appearing in the registry). However, this relies on clinicians remembering to register the patient as soon as they meet the inclusion criteria. Electronic health records can help here in a number of ways, either automating the process of flagging eligible patients for extraction to the registry or producing a list of eligible patients for manual reporting at agreed intervals.
The frequency of follow-up also needs consideration, but as long as all eligible patients are included in the registry, the follow-up of patients can be carried out at intervals, e.g., quarterly or annually, with dates captured for all data elements and outcomes.
As with other design aspects, careful attention must be paid to the burden of data collection on clinicians and patients. It is better to have a small dataset of high quality covering an entire (or representative) population than a large dataset of low quality covering a selection of the population.
If your registry has only descriptive objectives or is primarily for quality assurance you may not need to consider the size it needs to be to have the statistical power to address an objective. In these cases, practical considerations may limit your registry’s size and scope, though it will still be desirable for your registry to represent the whole population. Ideally, the registry will include the entire population with the condition of interest.
If your objectives are limited to comparing the effectiveness of treatments, which don’t require your registry to be representative of your country, you will need to look at a range of assumptions about the size and duration of your registry and consider what statistical power you will have to be able to detect differences. As part of your governance work, you will need to be able to justify the number of patients included in the registry and the processing of their data.
- The expected timeframe of your registry and the time intervals at which analyses of registry data will be performed
- The expected size of clinically meaningful effects or the desired precision of the effect estimates
- Whether or not your registry is intended to support regulatory decision-making
- Whether multiple comparisons are going to be made
- Whether high levels of attrition or non-adherence to therapy are expected
Appendix A in the AHRQ guidelines covers the topic of study size calculations for registries, which is also covered in one of the ERA Registry’s educational series. You may need to consider additional factors when determining the most appropriate registry design. If you are planning a product safety registry, a rare disease registry, a medical device registry, or a quality improvement registry, the last section in Chapter 3 of the AHRQ guideline highlights some additional design issues you should consider.
There are so many things to consider and perspectives to take when designing a registry that it can be helpful to use information systems methodologies to create a series of models to summarize things in ‘pictures.’ These reduce the distraction of small details and help you to see how the ‘real world systems’ of your registry work with each other.
While it is important to involve information systems experts in this process at an early stage, their role should only be facilitative. The involvement of content experts (usually the clinicians and patients for renal registries) is vital, with good communication between all team members.
There are a number of methods that can be used to create these models, such as Unified Modelling Language and business process modelling. In general, these methods begin with the information systems expert conducting semi-structured interviews with content experts before an interactive
workshop is held to build the model through consensus and resolve ambiguities. For further details on specific methods for creating these models, see Chapter 6.5 on the PARENT guidelines.