
Trial design
The design of a clinical trial describes a sequence and structure of activities aiming to reveal a cause and effect relationship – defined in the research question. All trials begin with a single group of participants (the COHORT) who are selected to represent a defined disease population. In most comparative clinical trials, a cohort is then divided into two or more groups subjected to an intervention and comparator. The groups are then observed for the OUTCOME of interest. The difference in outcome between the groups is then calculated to determine the effect of the intervention.
These four factors can be summarized by the acronym PICO.
- Population
- Intervention
- Comparator
- Outcome
Together they provide the Trial Question: In the trial population, what is the difference between the intervention and comparator arms, in terms of the outcome ?
Together, Population, Intervention, Comparator and Outcome (PICO) define a precise trial question and guide all subsequent design choices.
Once the trial question is defined, you can choose a trial design. There are four main clinical trial designs:
This is the most common trial design. Participants are randomized to different groups (sometimes referred to as ‘arms’) which receive the intervention (often referred to as treatment or experimental arm) or comparator (which may be a control, placebo or active comparator). The groups are then followed for a specified time (the study duration) and the outcome is measured. Parallel-group trials usually have two groups, but three or more groups are sometimes used (e.g. in a three group trial the intervention can be simultaneously compared against the standard treatment and against placebo). Adding more groups means that more participants have to be recruited in order to maintain POWER (the study’s chance of finding a difference in outcomes between the intervention and the comparator, if a true difference does exist).
Depending on the statistical methods (see Statistical Analysis), parallel-group trials can test for superiority (that the intervention is better than the comparator), non-inferiority (that the intervention not worse than the comparator) or equivalence.
Parallel-group trials are necessary to test the effect of interventions on most important clinical outcomes. Unlike cross-over trials, they can test the difference in disease progression (eg. worsening proteinuria or renal function) or in adverse clinical events (eg. need for blood transfusion, bloodstream infection, acute transplant rejection or death). However, compared to cross-over trials, parallel-group trials often require longer follow-up times and larger sample sizes to assure power.
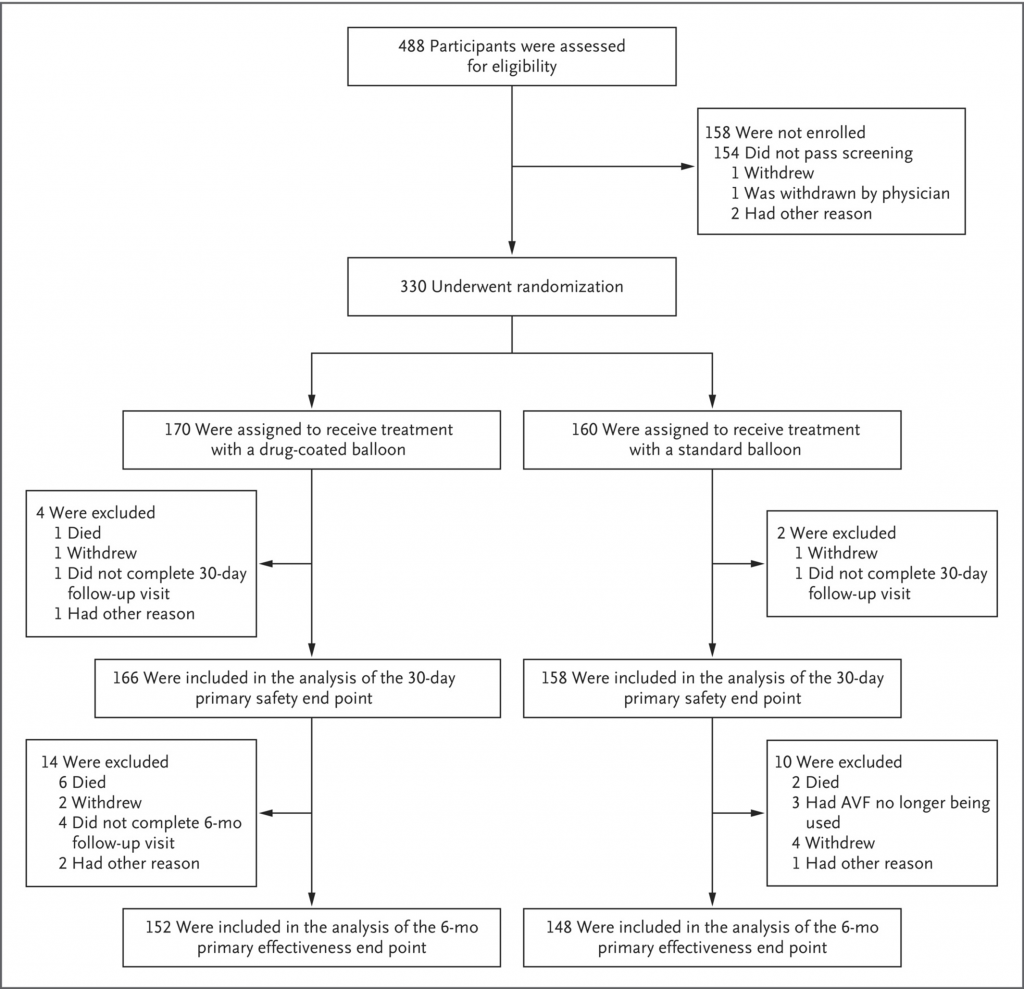
In a cross-over trial, participants receive both the intervention and the comparator but at different times. So a participant who starts receiving the intervention will change to comparator in the second half of the study, and vice-versa.
Cross-over studies are suited to study the effects of interventions on short-term changes in reversible outcomes (e.g. blood pressure, serum phosphate or pruritis). Because each participant acts in both the intervention and the comparator groups, the variation within the cohort is reduced. This allows cross-over studies to be smaller than equivalent parallel-group trials while maintaining study power.
On the other hand, cross-over trials must be careful to avoid bias caused by switching treatments. It is necessary that the underlying disease state or condition remains stable through the study period and that the effect of the intervention does not carry over into the comparator period (or vice-versa). Most cross-over studies use a wash-out period to avoid this latter problem. In addition, it’s critical that the order of treatment does not interfere with study results (e.g. if the intervention cures or permanently changes the disease state).
![Flow diagram from Saran et al. [Saran R, et al. Clin J Am Soc Nephrol. 2017 Mar 7;12(3):399-407 PMID 28209636]](https://www.theisn.org/wp-content/uploads/2020/08/clinical-trials-cross-over.jpg)
A factorial trial is a parallel-trial in which two sets of intervention and comparator are tested simultaneously. They are also known as 2 by 2 studies as they divide patients into four groups which can be represented in a 2×2 table. They increase trial efficiency by using one cohort to test two different trial questions. In addition, they can also test if the combination of interventions has a different effect to either on their own. Note that despite having two interventions there will be still only one outcome (i.e. one P, two Is, two Cs and one O). The main disadvantage of this type of trial is the large sample size required to achieve enough power. Another issue is that its design adds complexity to the implementation and analysis of the results.
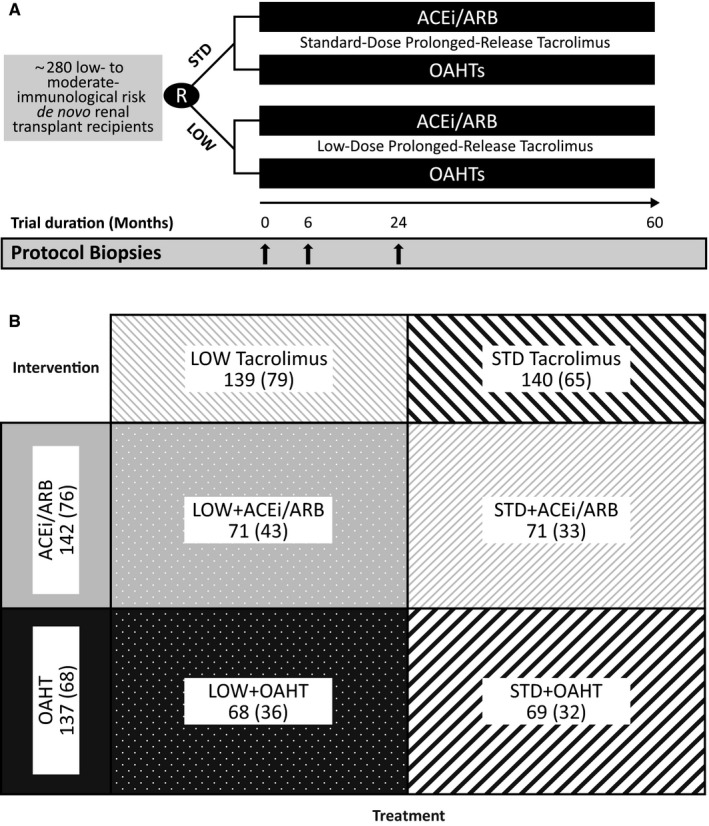
Cluster trials differ from the other types in that groups of participants are allocated to different treatments – not individual participants. They are most useful when the trial intervention is a health care practice rather than an individual treatment. Examples include such practices as the use of antimicrobial detergents in hospital cleaning products. In this example, all the patients at the hospital are affected by the practice and so you could not effectively split them into groups. Cluster trials avoid this problem by involving multiple groups of patients (eg. hospital, clinics or dialysis shifts) and allocating whole groups (i.e. clusters) to the intervention or comparator. The outcomes of individual patients are then compared using statistical methods that account for the fact that patients were grouped together in clusters. Cluster trials are specialized and will not be discussed further.
Once you have your PICO trial question and have selected a trial design it is time to consider your planned trial in more detail. Considerations will include the detail of Endpoints and outcomes, Sample size calculations, Study Protocol, Randomization, Patient and site recruitment, and Funding.
- Appel LJ. A primer on the design, conduct and interpretation of clinical trials. Clin J Am Soc Nephrol. 2006;1(6):1360-1367. [DOI https://doi.org/10.2215/CJN.02850806]
- Rethinking Clinical Trials [see Design/Endpoints and outcomes]
- Planning a Randomised Controlled Trial
- UK Trial Manager’s Network: The Guide to Efficient Trial Management
- Field Trials of Health Interventions [see Chapter 4: Trial Design]
- European Patient’s Academy: Clinical trial designs